日々大量のデータを取り扱う方にとってエクセルはとても強い味方です。特に、分析や解析を行う方にとって各種の関数はなくてはならない存在だと思います。合計、平均、標準偏差・・・様々な数値をいとも簡単に計算することができます。多機能すぎて使いこなすのも難しいほどですよね。筆者もかつて、いわゆる「ビッグデータ」の取り扱いに随分苦心した経験があります。
この数字はこれでいいの?
よくもなく・・・わるくもなく・・・そこそこですかね。
こんなやりとりです。
こんな状態を脱却するために、エクセルを活用した対応方法を考えてみます。
大量のデータを取り扱っているが、ただデータを眺めるだけではこれ以上前に進めないと考えている方に、新たなデータの切り口とエクセルでの処理手法を提案できると思います。活用することで、今よりも正確にモノゴトが判断できるようになり、先ほどの筆者困ったケースでも明確に回答できるようになると思います。
手法としては、ビックデータを「正規分布」の形にエクセルで処理し、処理したデータやグラフを元に考えるというやり方です。
ルーチンで取得しているデータや、自動で収集されてくるデータがあり大量の数字に囲まれる中で、データを比較してみたり平均値を求めてみたりとエクセルで処理をする際、もう少し今まで取得している大量のデータを有効活用して、これまでの経験を踏まえた上で今の状態を考えてみたいという場合、少し工夫が必要になりますよね。
工夫の一つとして、正規分布を活用する方法があります。取得したデータは正規分布に従うことが多いという経験則に従えば、大量のデータを正規分布の形に処理し直すことは意味があります。
取得している大量のデータがあり、エクセルが使える環境があるなら、正規分布でデータを表現する手段を理解しておくことは多くのメリットにつながります。
「良いか、悪いか?」の問いに対して明確な根拠を持って、迅速に回答できるようになることで、迷うこともなくなると思います。
処理方法は簡単ですので、是非ご活用ください。
Excelを使ってデータを正規分布で表す
正規分布
「正規分布」ときくと「???」となる方がいるかもしれませんが、今回はイメージだけつかんで頂ければ結構です。
統計学などでよく出てくる内容ですが、説明については別途詳しくするようにしたいと思います。
このようなイメージのグラフみたことはないでしょうか。
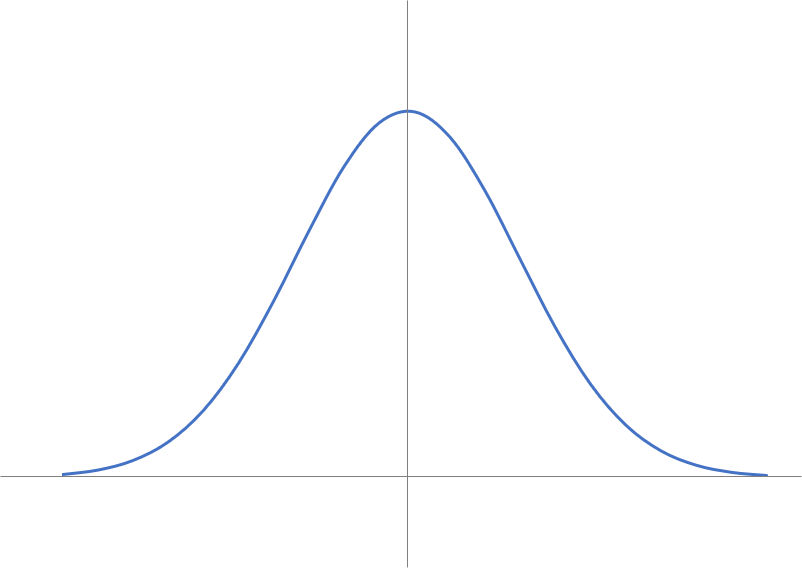
このような形にデータが分布する状態を正規分布と理解してもらえば大丈夫です。
エクセルで正規分布を描く
エクセルで正規分布を描くには、NORMDISTという関数を用います。手元のデータにいくつかの処理を施して、この関数を使えば正規分布を得ることができます。具体的に考えてみます。
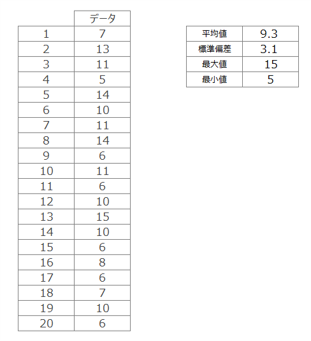
Step1:データ収集と一般統計量の整理
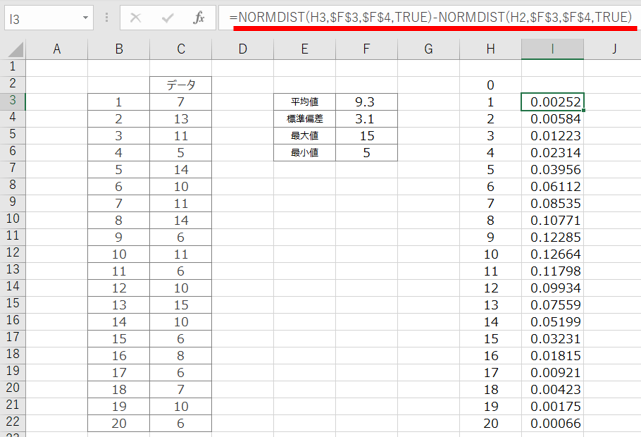
まずは、下図1のようなデータを考えます。今回のデータは5~15の間で発生させた乱数となっています。データに対する、平均値・標準偏差・最大値・最小値を記載しています。この辺りが一般的な統計量かと思います。
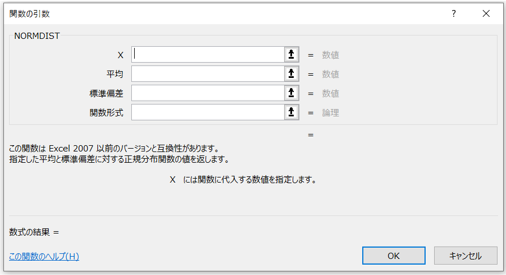
Step2:関数NORMDIST確認
今回使用する関数NORMDISTです。入力項目は4つで、x(実際の数値)及び平均、標準偏差、関数形式です。今回関数形式に関しては、「TRUE」のみ用います。
Step3:計算する
0~20の横軸に対して
NORMDIST(x, 平均値, 標準偏差, TRUE) – NORMDIST(x-1, 平均値, 標準偏差, TRUE)
を計算する。ひとつ前の数を引いておかないと、累積表示されてしまうのでイメージ通りのグラフができあがらないので注意してください。
Step4:グラフ化
Step5:縦軸変更
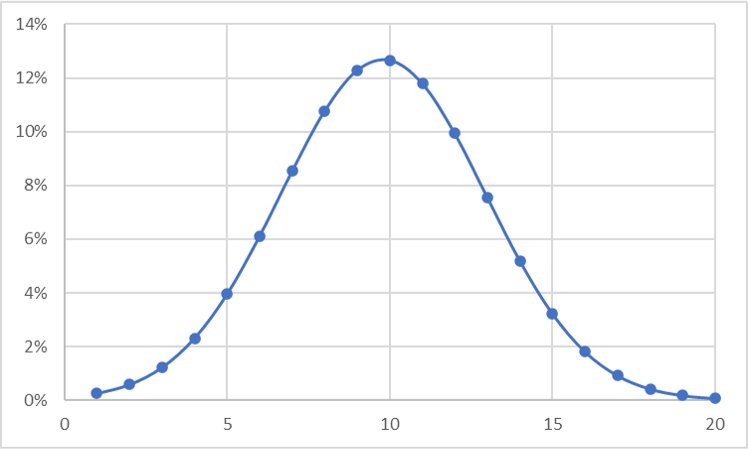
縦軸を%表示にして、どの数字が何%程度発生するかを観察する。
以上で作成は完了です。以下グラフの考察を行います。
考察する
今回の例でいうと、10が12%程度の発生率となっていて最も高いです。5~15の範囲ですので5や15に近づくにつれて発生率が下がっていることが確認できます。0~5の間や、15~20の間は数字が発生しませんが、確率論の話ですので「0%」にはなっていません。こんな風にみると、5や15という数値が何回も連続で発生したりするのは確率で考えると何となく変だとわかりますね。
まとめ
エクセル関数NORMDISTを使って、正規分布で表現する方法を考えてみました。
ビックデータを取り扱う場合、データが大量にあるので一つひとつのデータが良いのか、悪いのかうまく判断出来ない問題に対して、知見として得られているデータを正規分布すると考えて処理して、もう一度得られたデータを見直すことで確率という数値で判断を行っていくことができます。
今回ご紹介したのはほんのさわり程度です。もっと活用することも可能ですので、また機会があればご紹介したいと思います。
当ブログでは実際の仕事での経験を通して、役立つノウハウの蓄積を図っています。お時間があれば以下のリンクより、色々な記事を読んでいただければと思います。

ここまで読んでいただき、ありがとうございました。



コメント